废话前言
感觉自己很长时间没有跟进技术发展了,随着大模型越来越火,我迫切感受到需要加紧跟进这方面的技术。不过我不打算选择语言大模型,这个相对比较成熟且大家都在卷的路线,我打算开视觉大模型来追赶。原因除了语言大模型比较卷且估计没啥能做的之外,另一点是出于对图像更为本质的个人偏好。或者说,凡眼所能观,皆为图像。文字其实也只是特殊的图像,只是因为好处理,目前被抽象成了token,去做更进一步的事情(更方便去做其他事情,比如推理,思维)。但是视觉是更本质的,尤其是中国文字博大精深,我可以凭空造出一个从来不存在但是大家也能看懂的图案————就像武则天造字那样,去含蓄,综合的表达。
假如未来真有世界模型,那这个世界模型一定是以图像和音频为主导,不会是纯文字。文字可能只是一个抽象,只是为了方便做一些事情。
追赶专辑的第一篇,就是从Vision Transformers开始。从技术角度Vision Transformers是CNN的替代升级,虽然现在CNN也又大量应用,以及有一些工作我们会看到,结合CNN和Transformers。但不可否认的是Transformers有一些天然的优势,比如说它的输出可以不是一个分类结果,而是一些描述,即我可以很自然地把图像和文字结合或者转换成文字。不要小看这点,这意味着如果有需要,我可以总结图像且不丢失一些关键细节。这是以往CNN难以做到的,CNN会显得过于Task Specific。
追赶技术,最重要的就是找一个起点,好在网上也有大量类似的文章论文解读代码解析。这里我以知乎科技猛兽的Vision Transformer, LLM, Diffusion Model 超详细解读所列大致提纲,和他的解读为起点,主要总结一些Take Aways,加上自己的一些感受,如有不同观点,欢迎评论。
我会把看到的文章分为以下几类:【慢炖】【清炒】【煲汤】【雕花】【瀑布】,正如品菜做菜那样,也能希望有所收获。也方便后续如果有读者想要自己专攻看一些基础论文,进行选择吧
论文浅读
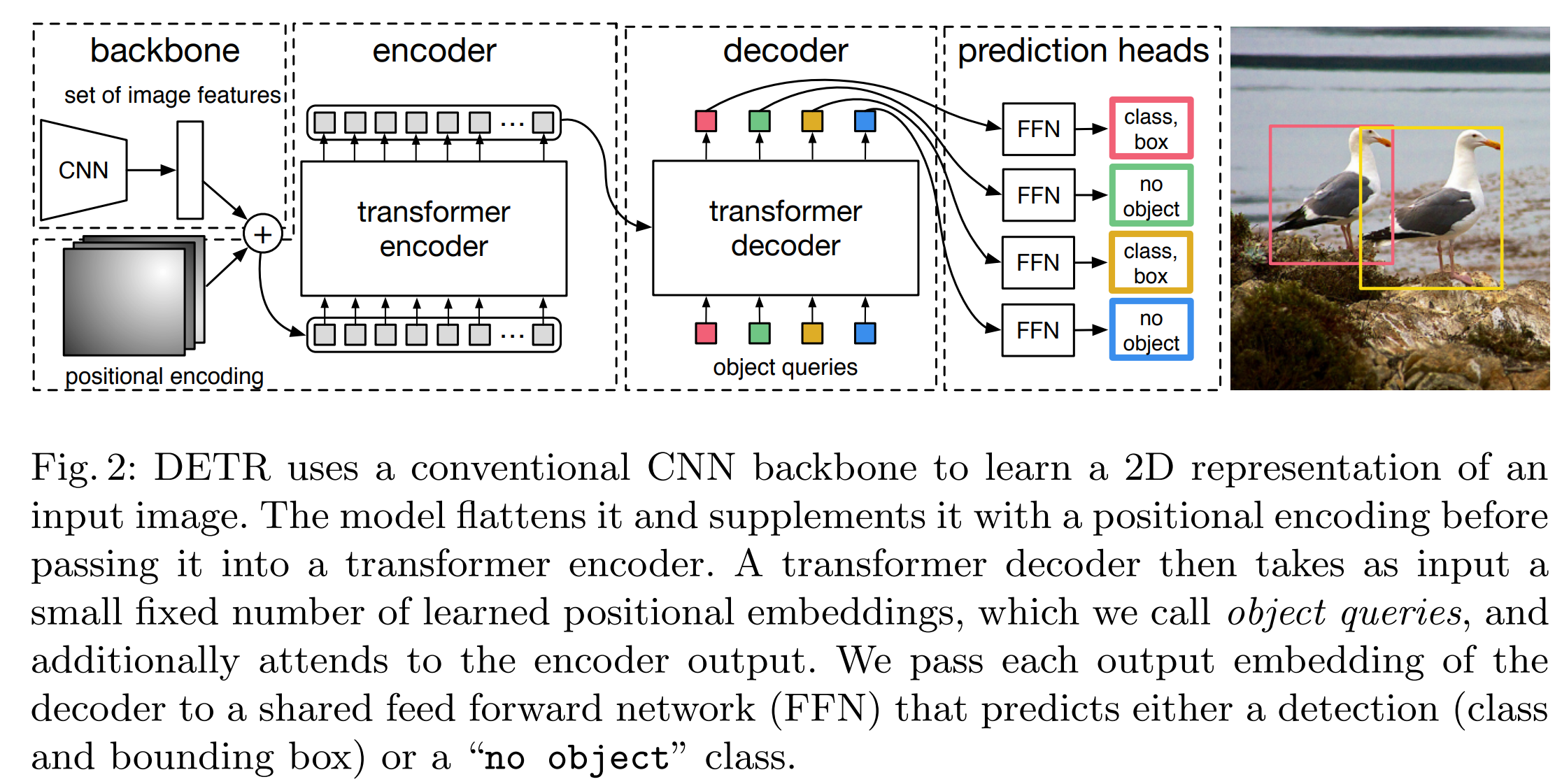
End-to-End Object Detection with Transformers 【慢炖】
简称DETR,FaceBook提出的端到端目标检测,是Transformer首次在CV领域的应用。
如图所示,主要的想法是
- Encoder-Decoder结构,先把图像Encoder,然后Decoder出分类和Bounding Box。检测目标最大数量上限是预设的。Loss采用二分图匹配,相当于预测和GT匹配最相近的来算loss,不考虑输出顺序。
- Encoder部分,NLP任务是把token转成id然后转成embedding,图像这边比较简单,直接CNN(backbone)之后,转成embedding。这里需要注意的一点是positional encoding。因为图像是二维的,所以x,y都要encoding,做法就是把embedding砍半,一半做x的positional encoding,一半做y的positional embedding。其实如果resize图片到固定大小应该也可以不用,但那样的话就不能处理不同大小的图片了(大图resize后目标可能很小)
总结下和原始transformer编码器不同的地方(from知乎):
- 输入编码器的位置编码需要考虑2-D空间位置。
- 位置编码向量需要加入到每个Encoder Layer中。
- 在编码器内部位置编码Positional Encoding仅仅作用于Query和Key,即只与Query和Key相加,Value不做任何处理。
一些实现细节
- Batch训练时候按最大的图来处理,其他图片padding 0。
- 为了使最终分类和bounding box不一样,decoder的object queries是一个可学习的positional embedding,初始化全0
- bounding box的格式(中心点x坐标,中心点y坐标,归一化宽度,归一化高度)归一化方式就是除以图片原来的宽和高
- 超参:AdamW优化器,10-4 LR,0.1 drop out,The weights are randomly initialized with Xavier initialization。backbone resnet-50,冻结BN,backbone LR 10-5比网络其他部分小有助于提升稳定性
- 整体网络结构,注意decoder有两个MHA,Q,K,V的来源不同,第一个只来自Object Query,第二个来自encoder的K和V

DETR应用衍生:还可以用于全景分割任务
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 【清炒】
如何使用Transformers来做分类任务。简称也叫 ViT
分patch,把图像分成例如 16 x 16的小块,过一个MLP提取embedding之后,按NLP的方式进行。需要注意的是这里只有Encoder结构,而Encoder的注意力是前后都能看的。所以这里加了个0 patch和特殊的class embedding。用来汇总所有输出->做分类任务。不用这个也行,也可以直接avg pool。另外我觉得这个不一定要加在最前面,也可也加在最后面,实际上DeiT就是这么干的
Training data-efficient image transformers & distillation through attention 【煲汤】

最大的区别就是加入了老师token,放在最后。然后做了蒸馏
Incorporating Convolution Designs into Visual Transformers 【煲汤】
先卷积再split。区别于先split再卷积
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows【慢炖】
这是Transformer在CV上的经典应用。首先图像不同于文本,一张高分辨的图会有很多像素,所以不能像NLP那样直接一股脑全丢进去。Swin Transformer借鉴了CNN时代常见的层级结构和多次降采样,设计仅由Transformers和MLP构成的模型并达到了当时分类领域的SOTA。
- 总共由4个阶段,从第二个阶段开始,每个阶段分别进行一次降采样和若干Swin Transformers模块,每降一次feature map的高度和宽度都减半,但是channel数翻倍(特征总量减少一半)
- PatchMerging的方式,就是把从头开始每次选相邻4个像素的featuremap concat在一起,然后过一个MLP,假设原来Channel数是C,concat完就是4C,此时高度和宽度已经减半,先LayerNorm,然后再过个MLP,channel变成2C
- WindowAttention,就是Transformer Attention的范围是局部的,如下图所示,每个Window 7x7 的大小,每个Patch只在Window内做Attention

Shift-WindowAttention,我看了很多blog,其实没太讲明白。我看过这样的观点,很认同:因为只在Window内做Attention,必然只有局部的信息,没有全局信息,那么怎么引入全局的信息,这里有很多种方式,比如你可以让各个Window还有个全局交互,或者像论文里的,把图片shift偏置一下继续做Window Attention,让Window内的节点和Window外的节点建立一些联系(因为Shift之后的新Window)。论文提到的方式并不是唯一的。然后我们再来看下做Shift,继续做Window Attention需要哪些改动。如下图所示,没有数字编号的并不需要mask,因为相邻关系是完整的。然后我们会发现左上多出来了一点,右下少了一点(导致不够做attention),最粗暴的方式,我们可以只增加右下的mask,把左上的内容丢弃了。但是这样似乎有些浪费,我们可以把左上的内容拼到右下啊,然后改一下mask,只允许他们自己做attention,这样保持相邻关系。
特别的原文代码,首先对mask区域做了划分,就像我画的图那样(当然数字编号不一定对的上,但是一个意思)H, W = self.input_resolution img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1 h_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None)) w_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None)) cnt = 0 for h in h_slices: for w in w_slices: img_mask[:, h, w, :] = cnt cnt += 1 mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1 mask_windows = mask_windows.view(-1, self.window_size * self.window_size) attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))然后通过squeeze和自动broadcast机制,计算一个 Window x Window 的mask
你可以理解为在算一个patch时候,其他patch需不需要做mask。显然只有rank一样的才不用mask。

后记
纯视觉的论文浅读就先到这里,其实还有Deformable的Attention,等后续有空再更。下个系列开始追赶多模态,主要是视觉+文本的